What an “AI-native” engineering team actually means (and what it doesn’t)
An AI-native engineering team is not a team that uses AI tools — it is a team whose workflow has been restructured around the assumption that AI assistance is the default at every step. In 2026, the defining marker is not how many AI tools are licensed, but how requirements are refined, how tests are scaffolded, how code is reviewed, and how architectural decisions are recorded. Done well, this lets a five-person team match the throughput of a much larger traditional team — at the cost of materially harder code-review discipline and clearer decision rights.
Most teams in 2026 use AI. Many fewer are AI-native. The difference shows up in the workflow long before it shows up in the output.
A team that uses AI looks like a traditional team with a Copilot subscription. Each engineer benefits individually. The team’s process — sprint planning, code review, release management — is unchanged. Gains accrue at the individual level and dissipate at the team boundary.
A team that is AI-native looks different. Requirements meetings have an AI participant that drafts user stories in real time and gets corrected on the spot. Test scaffolding is the AI’s job; engineers write the cases the scaffolding cannot infer. Pull requests carry a second reviewer that is non-human and always available. Architectural decisions are written down because the team has internalised that the AI’s future suggestions are only as good as the architectural record it is reading.
The Singapore maritime tech startups working out of Pier71 and the MPA Innovation Lab are useful case material here. We have seen multiple 6–10 engineer maritime tech teams in 2026 ship at a pace that would have required 20+ engineers three years ago. The throughput delta is real. It also has a price tag that most CTOs have not sized.
So what? The strategic question is not whether to adopt AI. It is whether to restructure the operating model around it. The first is shopping. The second is engineering economics.
The operating model: where AI leads, where humans lead, where they pair
The honest answer to “how does an AI-native team operate?” is not a slogan. It is a workflow map. Here is the one we use at MLTech Soft, derived from running an ISO 9001-certified delivery process across 80+ projects and updating it across the 2024–2026 tooling cycles.
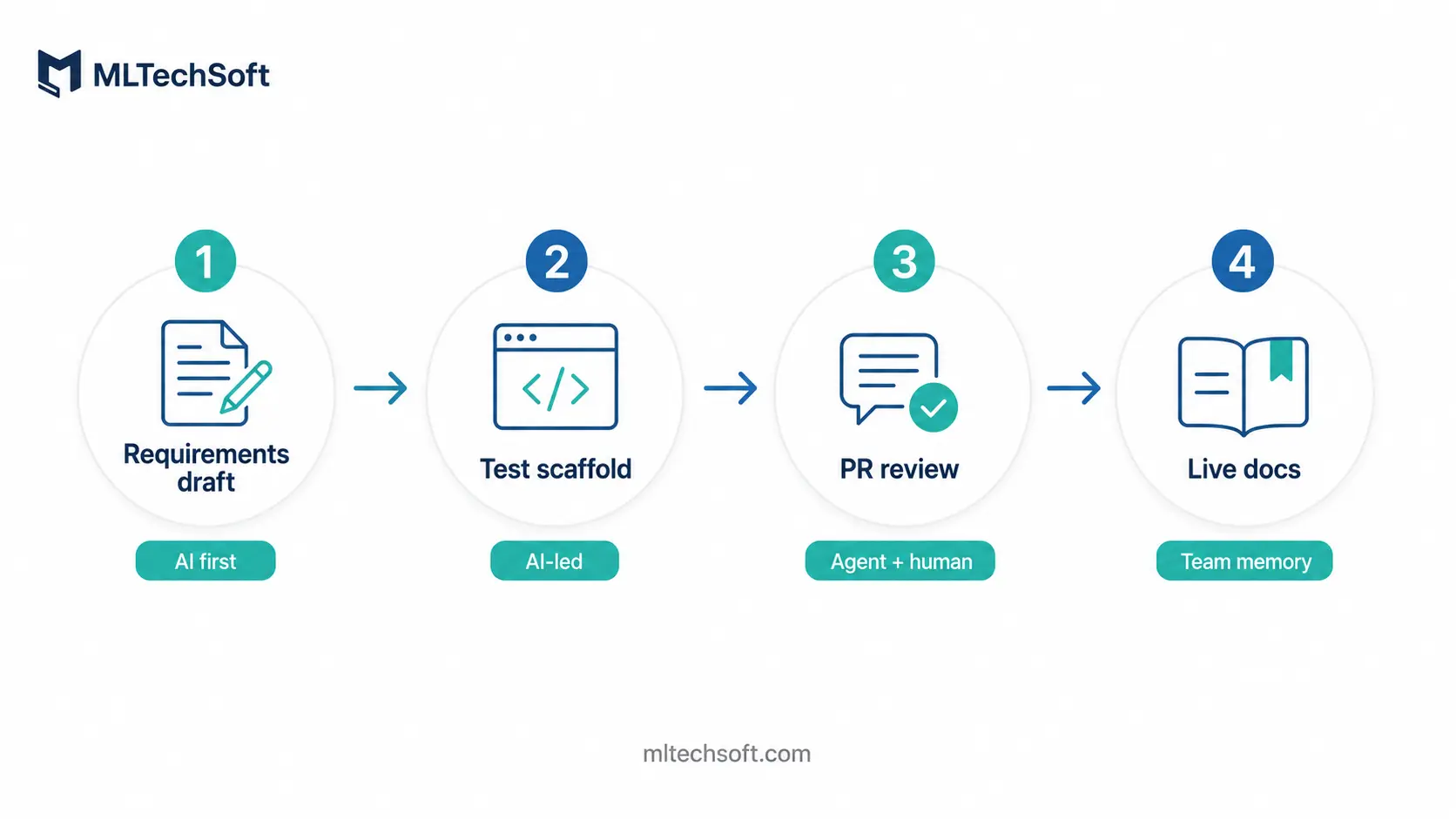
Requirements gathering and refinement
AI leads the first pass. A model trained on the project’s prior tickets, transcripts, and design notes drafts the user stories from a conversation transcript or a stakeholder note. The human-led step is the second pass: a product engineer interrogates the draft, removes the assumptions the AI invented, and adds the ones it could not have known. This usually halves the time from conversation to refined ticket.
The trade-off is that requirements quality becomes a function of how rich the project’s prior context is. New projects with no historical record do not benefit from this step. Long-running engagements, where the team has been writing things down for months, benefit enormously.
Test scaffolding and coverage expansion
AI leads almost entirely. Test scaffolding for a new endpoint, a new component, or a new integration is reliably generated and inspected by a human. Edge cases — the ones that come from understanding the domain rather than the code — are still mostly human-authored.
Here’s what this looks like in practice for a maritime engineering team: when an MLTech Soft engineer adds a new endpoint to a vessel scheduling change, the scaffolded tests cover the obvious shape — payload validation, success cases, common error cases. The engineer adds the maritime-specific cases the AI does not know to consider: a vessel whose ETA crosses midnight UTC into a different port calendar, a berth allocation that conflicts with a flag-state inspection window, a crew rotation tied to a specific port. The model writes the form; the engineer writes the domain.
Agent-paired code review
This is where most teams underestimate the work. AI-paired code review is not a button you press. It is a re-norming of the team’s pull request conventions.
A traditional team operates at a rate of perhaps three to five pull requests per engineer per week. An AI-native team produces three to five times that throughput, often more. Without changing the review process, the team is forced into rubber-stamping. With a re-normed process, the AI is the first reviewer — it surfaces clear issues, suggests fixes, and flags higher-stakes changes for human attention — and a human reviewer handles the genuinely consequential calls.
The discipline that matters: every pull request is tagged at submission as either “AI-led”, “human-led”, or “human-led with AI assist”. Each tag carries a different review checklist. AI-led changes get more scrutiny on subtle correctness; human-led changes get more scrutiny on architectural alignment. Without that tagging, the team eventually loses track of who actually wrote what — and that is the start of the AI-shaped tech debt nobody talks about.
Live documentation and architectural memory
Documentation in AI-native teams is no longer a chore. It is the input to every future task.
The architectural decisions, the ADRs, the system maps, the API contracts — all of these now feed the next agent prompt, the next test generation, the next requirements draft. Teams that write things down get compounding leverage. Teams that do not see the AI repeatedly suggest changes that fight the system’s actual design.
So what? The investment that pays back the most in an AI-native operating model is not the IDE upgrade or the model subscription. It is the team’s documentation discipline. That is the unfashionable answer.
Why team size is the wrong question — and what to measure instead
Headcount has never been a great proxy for engineering output. In an AI-native model, it is actively misleading.
The right metrics in 2026 are not “how many engineers do we have?” but “what is our team’s review throughput?” and “what is our architectural cycle time?” Specifically:
- Reviewed PR throughput per engineer per week, with the AI-led / human-led / human-led-with-AI-assist breakdown
- Time from architectural question to documented decision, measured in days, not weeks
- Coverage of the architectural record itself — what percentage of system behaviour is described in a document the next agent prompt could read
- Defect rate per 100 AI-led PRs versus per 100 human-led PRs, tracked over 90-day windows
Across the projects we have delivered, the teams that improve those metrics every quarter are the ones pulling ahead. The teams that hold them flat are the ones running an AI-adjacent operation — engineers using AI individually, with no team-level change in evidence.
A side-by-side picture is useful here.

So what? Walk into your next FY27 planning meeting with one of those metrics in hand, not a headcount target. The conversation changes from “approve the hire” to “approve the process change”. That is a more honest conversation.
Where AI still slows the team down
Every honest assessment of AI-native engineering has to include the work where AI is currently a tax, not a leverage. Three categories show up consistently across the projects we have run in 2026.
Long-lived, cross-cutting refactors. Anything that touches twenty or more files and requires a consistent intent applied across all of them is still faster with a senior human at the wheel. The model can do each file’s change but loses the thread of the unifying intent halfway through. The engineer ends up rereading the model’s output as if it were a junior’s, which is slower than writing it themselves.
Ambiguous regulatory or compliance requirements. When the requirement is “this must comply with the current IACS UR E26 and E27 cybersecurity rules and we are not sure exactly which audit path our flag state will require”, the model will produce confidently-wrong code. Maritime compliance is exactly the area where the AI cannot ask the regulator a clarifying question. The human must.
Greenfield architecture decisions on novel domains. When a Singapore maritime tech startup is building a category of product nobody has built before — say, a multi-port digital bunker delivery network — the AI’s training data is thin. The architectural moves the model suggests are derived from adjacent domains and frequently miss the constraints that only a maritime engineer would know. The model is helpful at the implementation stage. At the architectural stage, it is noise.

The trade-off in one sentence: Teams that pretend AI is always faster end up with a slow tail of work that quietly eats the gains; teams that name the slow work explicitly and route it to humans capture the wins without paying that tax.
So what? Build a “do not delegate” list. Make it visible. Train new joiners on it. The list will shrink over time as models improve, but in 2026 it is still long enough to matter.
What this means for hiring and budget in FY27
The most common FY27 engineering planning mistake is treating AI as a discount on headcount. It is not, in either direction.
The first-order effect is that a well-structured AI-native team needs fewer mid-level engineers per unit of output. The second-order effect is that the same team needs more senior engineers — because every PR now lands on a senior reviewer, and the AI-shaped tech debt risk is real. A team that flattens its seniority distribution to capture the savings is the team most likely to ship its way into a maintenance crisis in 2027.
The honest budget shape we see working in 2026 has three components. First, a smaller core team with a steeper average seniority — fewer engineers, more of them senior. Second, a meaningful line item for the AI tooling stack, the agent infrastructure, and the observability needed to run them safely. Third, a documentation and architectural-record investment that traditional budgets used to leave to “engineering will figure it out” — which is no longer good enough.
For Singapore-based teams considering an offshore-onshore model, this changes the conversation about external partners. The partner’s contribution is no longer just engineer-hours. It is whether the partner already operates with the review norms, the documentation discipline, and the ISO-grade process that makes an AI-native operating model survive contact with enterprise reality. Across our 30+ engineers spread between Vietnam and Singapore, that operating model is now table stakes — we treat AI-generated changes as a first-class category of pull request, and the review checklist for them is different from the one for human-led changes.
So what? When you present the FY27 engineering budget, the line that should generate the most conversation is the tooling-and-architectural-investment line, not the headcount line. If it does not, the plan is probably AI-adjacent, not AI-native.
Are you AI-native or just AI-adjacent? A checklist
A short, honest test. If you cannot answer “yes” to most of these, your team is AI-adjacent today — useful, but not AI-native.
- Do new user stories get an AI first draft before a human reviews them?
- Are tests for new code scaffolded by AI as a default step, not an experiment?
- Do pull requests carry a tag identifying whether they are AI-led, human-led, or human-led with AI assist?
- Does your code-review process apply different checklists to each of those tags?
- Is your architectural record machine-readable and used as context in agent prompts?
- Has your reviewed PR throughput per engineer per week at least doubled in the last 12 months?
- Have you written down the categories of work where AI is currently slowing the team down?
- Does your FY27 plan include an explicit tooling-and-architectural-investment line, not just headcount?
- Have you adjusted the seniority distribution of the team to absorb the new review load?
- Has the team’s documentation discipline tightened, not loosened, since AI tooling was adopted?
So what? A team that answers “yes” to fewer than half of those questions is leaving most of the available leverage on the table — and is statistically the team most likely to be surprised by another team’s output in twelve months.
FAQ: AI-Native Engineering Teams in 2026
Will an AI-native engineering team replace junior or mid-level engineers? Not in 2026, and not in 2027 on the trajectory we are watching. The shape of the team changes more than the headcount. Junior engineers in an AI-native team move faster on routine work and learn the codebase faster, because the assistant explains it on demand. The need for more senior engineers — to handle review, architecture, and the work where AI still slows the team down — usually increases. The teams that have flattened their seniority distribution have generally regretted it within two release cycles.
What is the difference between AI-assisted and AI-native engineering? AI-assisted engineering is individual: each engineer uses AI tools to be more productive. AI-native engineering is team-level: the workflow, decision rights, code-review process, and architectural documentation have been redesigned around AI assistance as the default. The performance difference between the two looks small from outside the team and is dramatic from inside it.
How do AI-native teams handle code review without rubber-stamping? By tagging every pull request as AI-led, human-led, or human-led with AI assist, and applying a different review checklist to each tag. The AI is the first reviewer on most changes; a human is always the deciding reviewer on consequential ones. The discipline that makes this work is the team’s willingness to enforce the tag at submission and to apply the right depth of review to the right tag. Without that discipline, the throughput gains turn into latent defects.
What does it cost to move from an AI-adjacent to an AI-native team? The model and tooling licences are a small fraction of the total. The dominant cost is the operating-model change: documentation work, process retraining, the new review norms, and the senior engineering capacity to land them. For a 10–15 engineer team, expect a multi-quarter transition that improves throughput continuously, not a one-week tooling rollout. Most teams that report “AI made us 10x” inside one quarter are reporting individual gains, not team-level transformation.
Can a Singapore maritime tech startup operate AI-native with a small founding engineering team? Yes, and this is where the leverage is biggest. A 4–6 engineer maritime tech team building inside Pier71 or the MPA Innovation Lab can deliver MVP scope that would previously have required a 12–15 engineer team — if the founder-CTO has been intentional about the operating model from day one. The startup advantage is that there is no legacy process to unwind. The risk is the same risk every small team faces: thin senior review capacity, which an AI-native model places more weight on.
The Short Version
AI-native engineering team productivity is not a tooling story. It is an operating-model story. The teams pulling ahead in 2026 have restructured how requirements flow, how tests are written, how code is reviewed, and how architecture is recorded. They have also written down — and routed away from AI — the small set of activities where the model is still a tax.
The CTO question for FY27 is no longer “do we need more engineers?” It is “have we rebuilt the workflow to deserve the productivity gains we are claiming?” The teams that get to “yes” on that question will ship at a pace that quietly redraws the competitive map. The teams that do not will hire to compensate, and find that hiring no longer closes the gap.
The difference between AI-native and AI-adjacent is not visible from outside. It is brutally visible from the next quarter’s release pace.
Next step: If you are restructuring your engineering team for an AI-native operating model — or evaluating whether to extend your team with an offshore partner that already operates this way — MLTech Soft offers a complimentary one-hour review of your current delivery workflow. We look at where AI assistance is currently producing returns versus tech debt and leave you with a written summary. Get in touch via the contact page at mltechsoft.com.




