Any enterprise software roadmap dated 2027 must plan for five concrete shifts: agentic AI moving from demo to default inside enterprise applications, ambient compliance replacing periodic audits, edge-deployed AI inference becoming a baseline pattern, sovereign data corridors reshaping APAC architecture decisions, and the disappearance of standalone reporting tools into the application layer itself. The 2027 roadmap is not about adopting AI. It is about whether the data layer underneath is ready for AI to act on it safely.
The 2027 Roadmap Question Most CTOs Are Quietly Avoiding
Almost every FY27 IT strategy deck has a slide that says “AI everywhere.” Almost none of them have a slide explaining what their existing data layer would need to look like for “AI everywhere” to work. That gap is where roadmaps fail.
A 2027 roadmap that lists agentic AI as a priority but does not address data quality, audit trails, and the permission model is a wish list, not a plan. The architectural truth is plain: an agent acting on enterprise data is only as safe as the smallest weakness in the data it reads, the actions it can take, and the log of what it did. Most enterprises in 2026 do not yet have a unified answer to any of those three. That is the work to schedule.
The five shifts below are the structural changes that will be visible in the 2027 reference architectures of the most serious enterprises in APAC. Each shift is presented with what it changes about software architecture, the question to put to any vendor selling into it, and the question to put on the next executive committee agenda.
Shift 1 — Agentic AI Moves From Demo to Default
By the end of 2026, around 40% of enterprise applications will integrate task-specific AI agents, per Gartner — by 2028, the projection rises to 33% of enterprise applications being agentic at the workflow level. The architectural consequence is that enterprise software stops being a system of record and starts being a system of action.
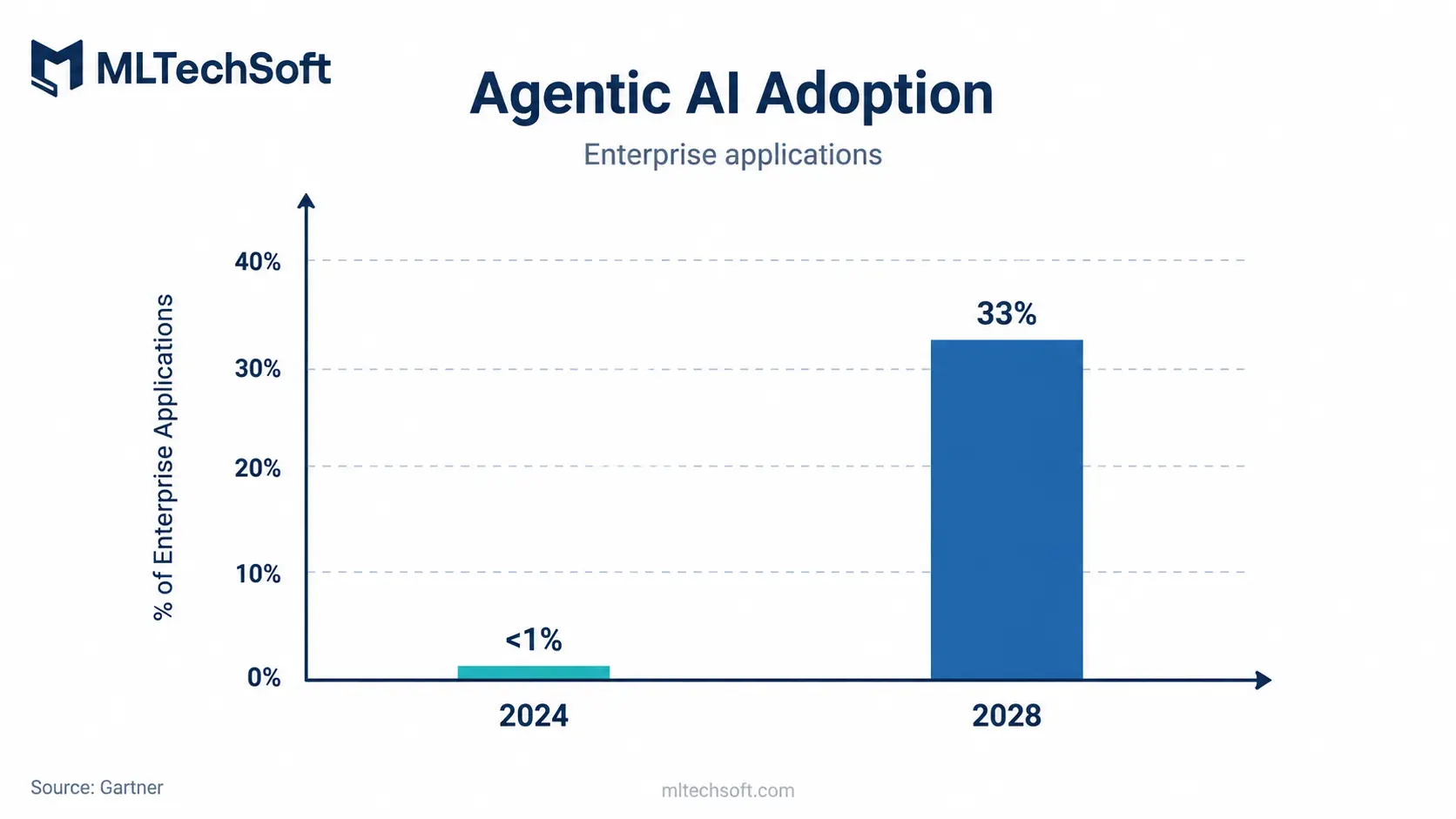
A system of record stores state and waits to be queried. A system of action reads context, decides what to do, and either does it or proposes it for review. The shift sounds incremental. It is not. A system that takes action needs a permission model that knows what the agent is allowed to do on whose behalf, an audit trail that captures intent and outcome, and a rollback path for actions that turn out to be wrong. Most enterprise systems in 2026 do not have any of these designed in.
What changes architecturally: the data layer is no longer optional. Agentic workflows need consistent, well-typed, queryable data with clean lineage. A “report-once-a-week” data pipeline is not sufficient.
The vendor question to ask: when your agent is acting, what is it allowed to do, who authorised it, and how is the action recorded? If the vendor cannot answer in plain language, the agent is not ready for production.
The board-level question: what is the one workflow in our business where an agentic system would create disproportionate value — and what data work would we have to do first to make it possible?
For a CTO running a mid-market enterprise in Singapore — say, a logistics services group with 400 staff across three countries and a 2011-era ERP at the centre of everything — this means agentic AI is not the project to start in Q1 2027. The project to start in Q1 2027 is the data and permissions cleanup that lets the agentic project succeed in Q4.
Shift 2 — Ambient Compliance Replaces Periodic Audits
Compliance in 2026 is mostly a quarterly or annual event. Ambient compliance is the architectural pattern that turns it into a continuous, software-mediated state — controls embedded in the application layer, with monitoring that produces an audit-ready record without anyone preparing one.
The forcing function is regulatory. The EU AI Act, NIS2, Singapore’s PDPA evolution, MAS guidance on AI in financial services, and the IACS UR E26/E27 cyber resilience requirements all share a structural assumption: compliance is something the system continuously demonstrates, not something a team scrambles to prove every twelve months. By 2027, Gartner projects that fragmented AI regulation alone will cover roughly 50% of the world’s economies, driving an estimated $5 billion in compliance investment.
What changes architecturally: compliance controls move from policy documents into code. Access decisions, data residency enforcement, model usage logs, and risk-tier classification all become first-class objects in the application schema.
The vendor question to ask: what does your system continuously prove about its own compliance — and how do you demonstrate it without a special audit project?
The board-level question: which of our current periodic compliance exercises would become ambient if we re-architected the underlying systems, and what would the saving be?
In our work on enterprise systems across maritime, FMCG, and healthcare clients, the consistent pattern we see in 2026 is that ambient compliance is most achievable for organisations that already operate ISO 27001-certified information security — because the operational discipline is already in place. The missing piece is the technical: turning a controls framework into runtime checks rather than annual evidence.
Shift 3 — Edge-Deployed AI Inference Becomes a Default Pattern
Centralised cloud AI inference is a fine pattern when the data and the user are both already in the cloud. By 2027, neither assumption holds reliably across enterprise workloads. AI inference at the edge — on factory floors, on vessels, in retail stores, in field equipment — becomes a default architectural choice rather than an exception.
The drivers are latency, cost, and data residency. A vessel running on a Southeast Asian transit cannot wait 800 milliseconds for a round trip to a US-East data centre. A factory line monitoring quality at high frame-rate cannot afford the cloud egress bill at scale. A regulated environment cannot send the data out at all. Edge inference solves all three by running the model where the data lives.
What changes architecturally: the model lifecycle becomes a deployment problem at fleet scale — versioning, rollout, monitoring, and rollback across hundreds or thousands of edge devices. The MLOps team starts to look more like a release engineering team.
The vendor question to ask: how do you update the model running on 500 edge devices, and how long does a known-bad version stay in production before you can roll it back?
The board-level question: which of our workloads is being held back today by the round trip to the cloud — and what would change if the model ran where the data is?
A practical example: a Singapore-headquartered logistics operator running 600 last-mile vans across APAC moved its computer-vision package-sorting model from cloud inference to edge inference in 2025 and cut average sort decision time from 240ms to 30ms — but had to rebuild its model release pipeline from scratch. The new release pipeline cost more to build than the model did. That ratio is typical, and it is the part that gets left out of vendor pitches.
Shift 4 — Sovereign Data Corridors Reshape APAC Architecture
Sovereign data corridors — the requirement to keep certain classes of data inside a defined jurisdiction, processed by defined entities — are no longer an EU-only concern. By 2027, every major APAC jurisdiction has either announced or implemented some form of sovereign data control, with Singapore, India, Indonesia, Vietnam, and China each taking distinct approaches.
The architectural implication for enterprises operating across APAC is that “deploy globally on one cloud region” stops being a defensible pattern. A multi-region, jurisdiction-aware deployment becomes the baseline — not because it is technically interesting, but because it is the only way to operate compliantly. For Singapore-headquartered enterprises with operations across the region, this is a 2027 architecture decision with a long tail of implementation work behind it.
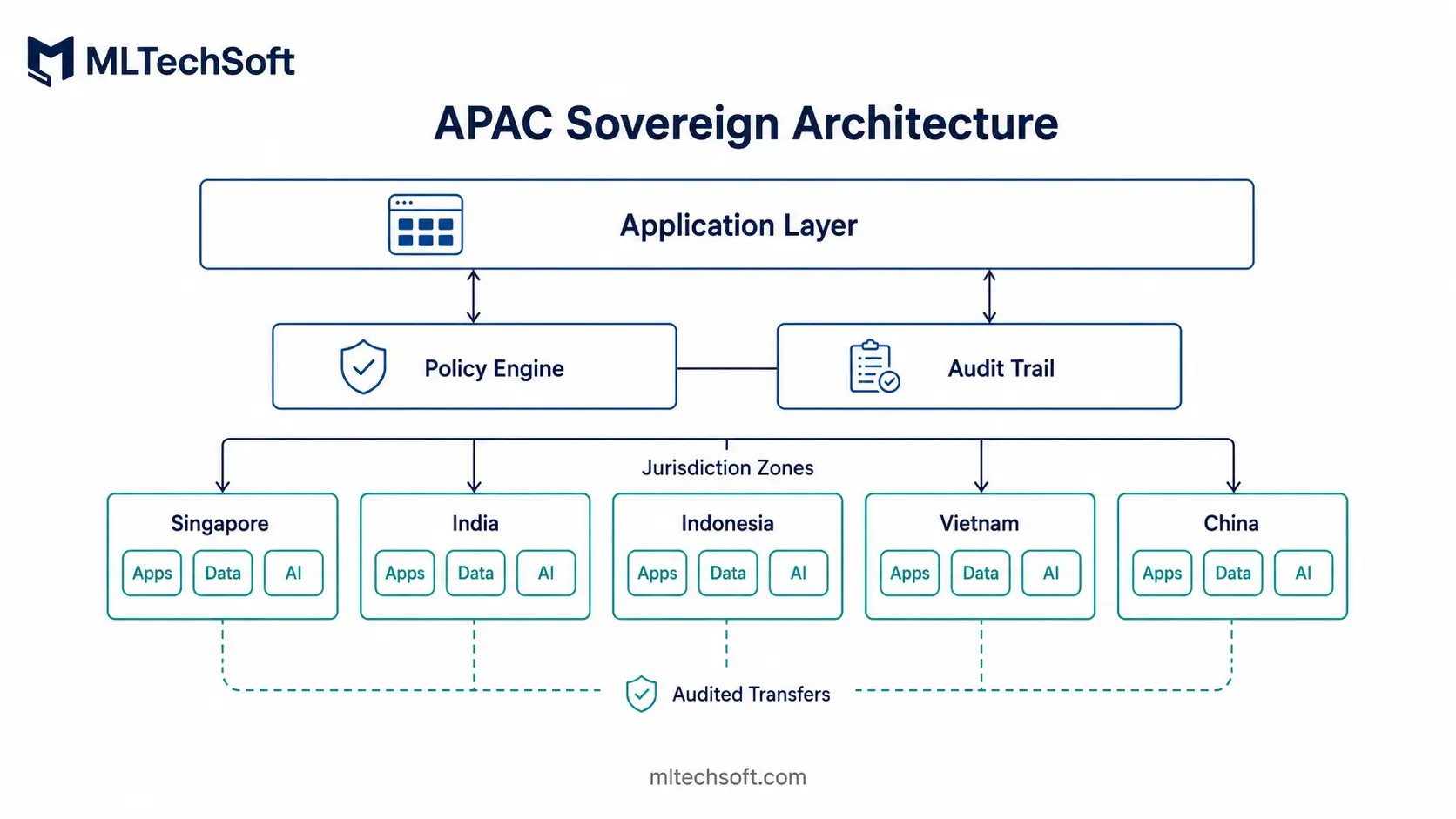
What changes architecturally: data residency becomes a first-class deployment constraint. Application logic, data storage, and AI model inference all need to honour jurisdictional rules per data classification. Cross-border data flow is a deliberate, auditable, and minimised operation.
The vendor question to ask: how does your platform handle data residency requirements that differ across jurisdictions where we operate — and where does the data physically sit, by class?
The board-level question: what would it cost us, in technical work and operational change, to operate a fully sovereign deployment across the five APAC jurisdictions we care about — and what would happen if we did not?
Our team’s delivery model — Vietnam-based engineering with a Singapore office and ISO 27001-certified information security — was originally designed around timezone and quality, but it has become directly relevant to sovereign data architecture in APAC: the same data classification, access, and audit discipline that satisfies ISO 27001 maps cleanly onto sovereign corridor requirements when extended properly.
Shift 5 — The Death of Standalone Reporting Tools
The standalone enterprise reporting tool — separate license, separate user base, separate data pipeline, separate skills — is in slow decline. By 2027, it is broadly absorbed into the application layer itself, with reporting and analytics becoming a property of every system rather than a destination users navigate to.
The driver is partly generative AI (“ask anything about your data”) and partly cost (“we are paying for three separate analytics stacks for the same data”). The architectural shift is that the application layer becomes both the source and the surface for analytics. Users do not leave the workflow to ask a question about it.
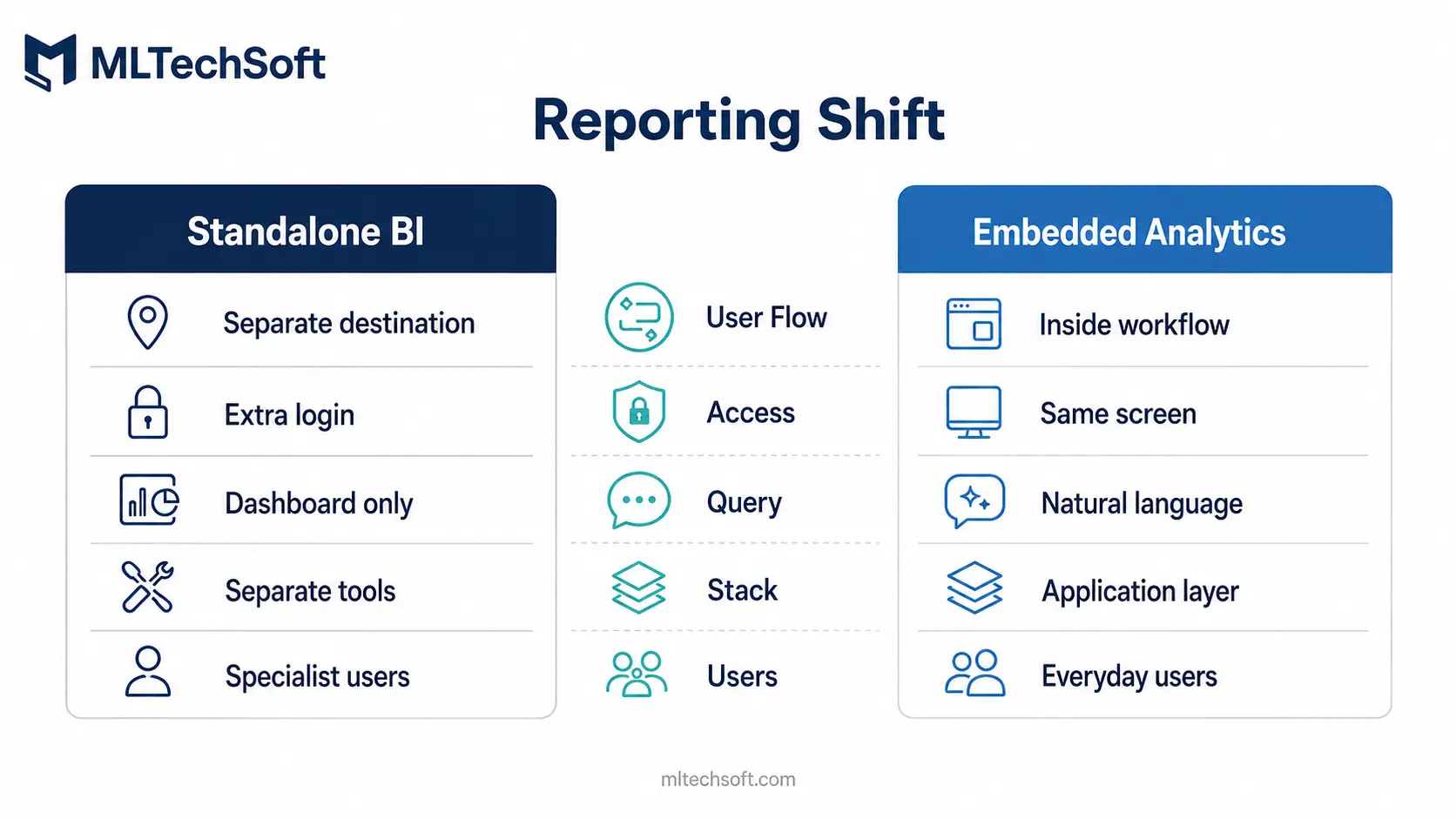
What changes architecturally: the data warehouse does not disappear, but the destination for most knowledge work moves out of it. APIs for natural-language data queries, embedded chart components, and contextual analytics inside every screen become standard.
The vendor question to ask: where do my users go to ask questions about their data — and how many separate logins, tools, and skill sets are involved?
The board-level question: which of our current BI licenses, dashboards, and reporting teams represent a 2027 line item we should not renew in their current form?
For a mid-market enterprise paying for two separate BI platforms and a third for embedded analytics, the implication is concrete: at least one of those line items is in scope for replacement by the application layer itself by 2027.
Why 40% of Agentic AI Projects Will Be Cancelled by 2027 — and How To Be in the 60%
Gartner’s projection that over 40% of agentic AI projects will be cancelled by the end of 2027 is worth taking seriously — not because AI does not work, but because most projects are pointed at the wrong layer.
The cancellations will cluster in three patterns. The first is projects that bought the agent before fixing the data: the agent is asked to act on data the organisation does not yet trust internally, and the project stalls in proof-of-concept. The second is projects that bought the agent without designing the permission model: the agent does something defensible but unauthorised, and the legal team kills it. The third is projects sold as agentic that were actually copilots: the value never materialised because the workflow was never redesigned around the agent.
Key projection: Gartner expects 33% of enterprise applications to include agentic AI by 2028 — and over 40% of agentic AI projects to be cancelled by end of 2027. The two numbers are not contradictory. The first describes adoption; the second describes the survival rate.
The way to be in the surviving 60% is mundane and unfashionable: spend the first two quarters on data quality, audit trails, and permissions before spending anything on the agent. The agent is a six-week project on a clean data layer. It is an 18-month rescue on a dirty one.
When we sit in 2027 roadmap workshops with CTOs across maritime, FMCG, and healthcare, the question that surfaces most often is not “which agent platform should we choose?” It is “how do we make our existing data layer ready for any agent platform?” The CTOs asking the second question are the ones whose 2028 retrospective will be a success story.
The Five-Question Roadmap Framework
The five shifts above can be checked against any vendor pitch, RFP response, or internal project proposal between now and December 2026 using a single recap table.
| Shift | What changes architecturally | The board-level question |
|---|---|---|
| Agentic AI from demo to default | Permission model, audit trail, rollback path become first-class | Which one workflow would justify the data work behind an agent? |
| Ambient compliance | Controls move from policy into code; continuous evidence | Which periodic exercise becomes ambient if we re-architect underneath? |
| Edge-deployed AI inference | Model lifecycle is a release problem at fleet scale | Which workload is held back by the round trip to the cloud? |
| Sovereign data corridors in APAC | Multi-jurisdiction, residency-aware deployment by default | What would full sovereign deployment cost — and what is the cost of not doing it? |
| Death of standalone reporting tools | Analytics absorbed into the application layer | Which BI line items will not be renewed in their current form? |
The trade-off is honest. Each shift has a cost. None of them are free. The roadmap that names the two it will commit to and the three it will defer until late 2027 is more useful than the roadmap that lists all five as priorities.
FAQ: Enterprise Software Roadmap 2027 Questions Answered
What is the single most important shift to plan for in a 2027 enterprise software roadmap?
Agentic AI is the headline shift, but the most important work is underneath it — data quality, audit trails, and permission models. The architectural reality of 2027 is that systems are increasingly expected to act, not just record. A roadmap that prioritises the action layer without the underlying data work is the one most likely to stall in proof-of-concept. The roadmap that prioritises the data layer first is the one most likely to deliver agentic value in production within 18 months.
How does ambient compliance differ from periodic compliance, in practical terms?
Periodic compliance is an event — an audit, a certification, an annual report — preceded by a special preparation effort. Ambient compliance is a state — the system continuously generates the evidence that controls are operating, with no special preparation needed. The practical difference is that an ambient-compliant system can answer any regulator’s question from its own logs, without a project to assemble the answer. ISO 27001-certified organisations are usually halfway there on the operational discipline; the missing piece is moving the controls from policy documents into code.
What does “sovereign data corridor” actually mean for an APAC enterprise?
Sovereign data corridors are the requirement to keep specified classes of data inside a defined jurisdiction, processed by defined entities, with cross-border movement constrained. For an enterprise operating across Singapore, Indonesia, Vietnam, India, and China, this means a single global cloud deployment is no longer compliant by default — each jurisdiction’s rules for personal data, sectoral data, and AI training data may differ. The 2027 architecture pattern is multi-region, jurisdiction-aware deployment as a baseline.
Is it realistic to remove standalone BI tools by 2027?
For most enterprises, yes — at least one or two of the standalone BI line items will be absorbed into the application layer by 2027, with embedded analytics and natural-language data queries as the new defaults. The data warehouse itself usually persists, because it serves analytical depth that embedded tools do not. The shift is in where users go to ask questions, not in whether the underlying data store still exists. The standalone destination tool, with a separate login and skill set, is what is in decline.
How should we structure our FY27 budget around these shifts?
The honest budgeting approach is to pick two of the five shifts to fund seriously and explicitly defer the other three to late 2027 or FY28. Funding all five at once is what creates the conditions for the Gartner-projected 40% cancellation rate. The two to pick should be the ones with the most direct line to a measurable business outcome in your sector — for most enterprises, that is agentic AI on one workflow and ambient compliance for one regulated process. The other three are credible roadmap items, not Q1 priorities.
What This Means for the Next Twelve Months
The 2027 roadmap is less about choosing AI vendors and more about choosing which architectural debts to repay before the AI vendors arrive in earnest. The five shifts named here will not all happen at the same speed inside every enterprise — but they will all happen, and the order in which an organisation tackles them determines whether the next eighteen months are progress or rework.
The CTOs who write the cleanest 2027 roadmaps are the ones who name the two shifts they will fund, name the three they will defer with reasons, and put a data and permissions cleanup project ahead of any agentic AI project on the schedule. That is the roadmap that survives contact with the budget committee and with reality.
If you are building an FY27 enterprise software roadmap and want a second opinion on which of these five shifts deserve real budget in your organisation, our team offers a free strategic technology assessment — a structured working session where we review your current architecture and flag the two shifts most likely to create or destroy value in your next 18 months. Book a slot here.




